The primary data stream from the FIRST survey consists of 5-second
samples of the correlated signal from each of the 351 VLA antenna pairs
in each of 14 3-MHz frequency channels in each of two IF bands, or 324,000
samples of the UV plane per 165-second integration. There are 215 pointings
per 10.5-hour day (including calibration observations),
or per season's
observing run. This data rate, along with the attendant requirement of
eventually producing
from these data 65,000
pixel images leads to certain
imperatives for the data reduction and analysis pipeline. It must require a
minimum of human intervention, and must be able to keep up with the data flow;
both objectives must be achieved without compromising the quality of the final
maps. Thus, we require a highly reliable, automated system which incorporates
optimal editing, calibration, mapping, CLEANing and coadding procedures. We have
designed, built, and tested extensively a pipeline system meeting these
requirements. The system uses three scripts based on standard AIPS tasks, but
incorporates several special-purpose tasks and modifications to standard
procedures which we have produced specifically for the pipeline. In this
section, we describe the innovative aspects of the pipeline developed for
FIRST; detailed descriptions of standard AIPS tasks are available in the
EXPLAIN files of the AIPS system.
Following standard FILLing of the data from the VLA on-line system, the phase and amplitude calibration is done using the calibration sources observed for this purpose. However, no data editing is carried out prior to pipeline processing. These raw UV data with initial calibrations applied are archived at the VLA and a copy is sent to IGGP/LLNL for pipeline ingest.
Two AIPS tasks, UVLIN and CLIP are used to flag bad visibility data resulting
from man-made or natural radio frequency interference, receiver problems, or
correlator failure. UVLIN is run twice, once at the outset with a threshold of
5 Jy, and again at the end of the self-calibration loop with a lower threshold,
determined with UVPRM and equal to the sum
of 10%of the zero-spacing flux plus (typically
Jy). After the first UVLIN run, the task CLIP
is run on a channel-by-channel basis with a threshold determined
again from UVPRM. For the second pass of UVLIN, the position of
the brightest source in the field is used as a temporary phase center, since
this facilitates UVPRM's ability to model the data owing to the slower changes
in the amplitudes of the UV components. These tasks are highly effective
in removing
corrupted visibility data. The message files generated by the two tasks are
examined in order to determine for which fields significant
(
) data loss has occurred; for the 1993 observing season, fewer than
2%of the 2153 fields were affected by interference at this level, and only
a small fraction of these require reobservation.
The problem of self-calibrating the visibility data had the potential of
requiring unobtainable levels of computational resources. To avoid the
necessity of repeatedly creating images, we have adopted a
number of efficient procedures. Before a single image is created, a search of
the Green Bank 20 cm and 6 cm catalogs
(Becker et al. 1991; White and Becker 1992) finds all sources with
mJy within 10 degrees of the field center. A tapered map
is then produced which includes the full area of the primary beam along with
a number of smaller images centered on
off-axis sources that, given the primary beam
pattern, will appear brighter than 2 mJy. The tapered image
as well as the satellite images are then searched
for all sources above 2 mJy. The positions and flux densities of these
sources are stored in a file for later use
(note that these files already constitute a radio source catalog superior to
any in existence). With this list of all sources contributing to a field,
it is possible to self-calibrate the data with roughly a dozen
pixel maps, rather than all-encompassing
images. If the
tapered map reveals any source brighter than 30 mJy, a three-iteration phase
self-calibration is carried out. In most cases, the phase changes resulting
from this self-calibration are less than
deg.
Before the data are imaged, the task UVFIX is run to improve the accuracy of the astrometric solution. The data are then passed through the task UBAVG which effectively increases the integration time where possible in order to reduce the total number of visibility points without degrading the final image. Natural weighting is used in gridding the UV data.
The final step before constructing the CLEANed image is to shift the center
of the map by up to one pixel () to assure that the
brightest source in the image falls precisely at a pixel center. This procedure
has been shown to reduce the sidelobe level from the brightest source in the
final map. The shift is determined from a dirty map made expressly for this
purpose; only fields with sources brighter than 25 mJy undergo this procedure.
A miscentered bright source is only one of the effects that produce avoidable sidelobes in the final image. Two others which we have attempted to avoid result from adding together data collected at several different frequencies. Since the primary beam response is frequency-dependent, a source at the edge of the primary beam where the gradient in the response is steepest can appear very different in the two IFs. Likewise, sources with non-zero spectral indices will also differ between the two frequency bands. Thus, if the two IFs are merged before mapping, the CLEANing process will not succeed in subtracting correctly 100%of the source flux, leaving behind unnecessarily high sidelobes. The obvious solution is to image the two IFs separately, but doing so reduces the UV coverage in the map which leads to larger sidelobes - just what we are trying to avoid. The solution to this dilemma is a compromise which we find produces maps with minimum sidelobe contamination.
Initially, we map and CLEAN the two IFs separately down to a flux density limit of 10 mJy using the newly created task WFCLZ (a modified version of WFCLN). Maps from WFCLZ are then written to disk with all the residuals set to zero. The CLEAN components from each map are subtracted from the visibility data of their respective IFs. The task WFCLN is then run on the two IFs combined until a CLEANing limit of 0.5 mJy is reached or 10,000 CLEAN components have been subtracted, whichever comes first. When this CLEAN is finished, the two earlier maps containing the bright sources are averaged together and added to the third image. Thus, the deep CLEAN is made with the full UV coverage, while the bright components have not been compromised by differences between the two IFs.
The final map suffers from significant distortion resulting from the use of a
two-dimensional FFT to approximate the curved celestial sphere (see Perley 1989
for a full discussion of this effect). This distortion is removed with the task
OHGEOM. Another small distortion, due to annual aberration, is removed by changing
the pixel size of each map by a small amount (typically 1 part in ).
The final images have systematic
astrometric uncertainties of
.
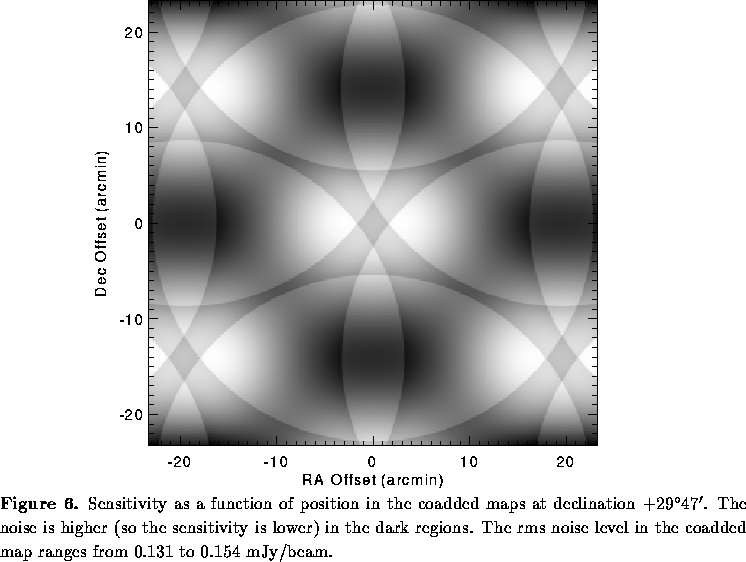
The final step in the pipeline is to sum adjacent images both in order to obtain
better signal to noise and to improve coverage uniformity. In general,
each field has significant overlap with 12 other fields in the grid. These
12 maps are truncated at a radius of , weighted by the square of
the primary beam response, and summed
(see Condon et al. 1994 for a full justification of this procedure). Given
the degree of overlap of the pointing grid, complete coadded images need be
constructed only for pointing centers in every other declination strip. The
resulting coadded images have a peak to peak sensitivity variation of only
over the entire survey region (Figure 6) and allow for the
detection of up to 50%more sources than are observed in the single field
images. The dynamic range of the final images is
.